
このコラムは、株式会社エル・ティー・エスのLTSコラムとして2013年2月に掲載されたものを移設したものです。
ライター

こんにちは、LTS業務変革支援事業部の山本です。
今回はビッグデータと言うキーワードについて書きたいとおもいます。ビッグデータという言葉が氾濫していますが、どうもあまり漠然としたキーワードで全体像をきちんと整理して説明している例は少ないように思います。
そもそもビッグデータとはなんでしょうか?辞書的な定義では「通常のデータベース管理ツールなどで取り扱う事が困難なほど巨大な大きさのデータの集まり」としています。この中には構造化データ(RDBMSに格納可能なデータ)だけではなく、非構造データ(音声情報、画像情報等)を含むこれまでデータ化が不可能だった多くの情報が含まれます。これらの情報から得られる示唆をビジネスに役立てようという概念全体を含めてビッグデータと括っているようです。
ではなぜビッグデータという言葉は全体像が掴み難いのでしょうか?そもそもビッグデータという言葉は「大量の多様なデータ」以上の意味を持ちません。その意味ではキーワード自体がはじめから漠然としています。例えて言うなら「大きな犬」「美味しいお酒」と同じくらい曖昧な言葉であり、この言葉の曖昧さを利用して多くのベンダーがそれぞれの都合の良いようにこの言葉を使うので厄介です。
ガートナーグループが定期的に発表しているハイプサイクル※1には多くの最新テクノロジ用語が散りばめられていますが、その中には「ビッグデータ」の文脈で登場する用語も多々あります。例えばインメモリDBMS、音声認識/マイニング、テキスト分析、M2Mインターフェース等です。
実は「情報」に関する技術でも例えば新しい情報収集技術(情報の電子化技術)である音声マイニングやソーシャルリスニングと、情報の高速処理技術であるインメモリDBMSやHADOOPは別のカテゴリに属する技術です。M2Mインターフェース等は分散された情報の結合技術と言ってもいいでしょう。このように全く違うカテゴリに属する技術を体系化しないまま、「ビッグデータ」というキーワードを理解しようとしてもなかなか上手くイメージすることができません。
各要素技術を大きく整理すると以下のようになります。なお以下に記載した用語はビッグデータの文脈で使われる用語のほんの一部ですが、大半の用語は以下の5つの円のどこかにマッピングできるはずです。
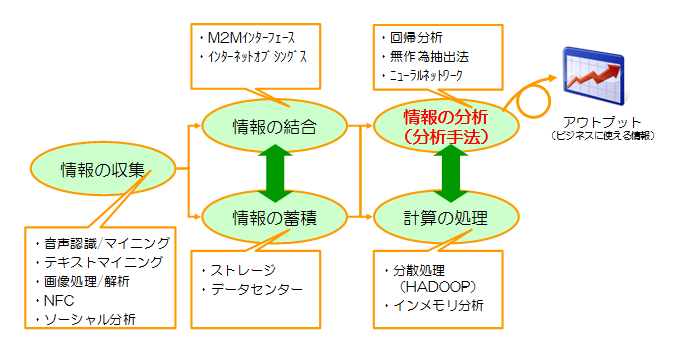
こうやってみると情報を収集、結合、蓄積、処理する技術はそれぞれ革新的な進化を遂げています。しかし実は情報を分析する手法は大きくは変わっていないのです。情報分析の手法にも幾つかの手法がありますが、ビジネスで使われる情報解析は大半が回帰分析です。回帰分析はある情報と強い相関性を示す他の情報(変数)を見つけ出す手法で、「オムツとビールの関係」がまさにこれに当たります。「オムツを買っている人はビールを買っている」という場合、関係する変数は2つですが、実際のビジネスではもっと複雑な関係性で「オムツを買う30代の男性は、A社のビールを好んで買う傾向にある」といったものです(変数が複数の回帰分析を重回帰分析といいます)。
昔はこの回帰分析を行うのに人がほとんど仮説を組んでいました。「AをしているBという属性の人は、Cという傾向があるはずだ」という仮説のもと、必要なデータを加工・処理してみて結果を確認する、という流れです。あまり多くのデータを処理しようとするとパンクする上、そもそも蓄積できるデータも限られていました。昨今は情報を収集する技術も貯める技術も処理する技術も飛躍的に向上し、複雑な計算を極めて短時間で処理できるようになりました。この結果「Cという傾向に強い相関性がある変数の上位3つを(膨大なデータの中から)見つけて来い」という大まかな指示でも有益な情報を見つけ易くなりました。
しかし技術の進歩で多少分析が楽になったとしても人間の要素が重要であることは今も変わりありません。人間の介在がなぜ必要なのかをまとめると以下の3点に要約されます。
【仮説を組むのは人間】
基本的な仮説を組み上げるのが人間であることには変わりありません。多少ざっくりとした指示でも機械が考えてくれる程度には技術は進歩していますが、どこからデータをとるのか、そのためにどのような収集技術を採用するのか、どの範囲までのデータを分析対象とするのか、データの結合は必要なのか、データ間の補正は必要なのか・・・。このような要素に適切な処理をしなければ有益な分析は出来ません。
【情報を読み解くのは人間】
分析の結果、ある情報と情報の間に相関性が見つかったとしてもそれがどのような意味を持つのかを読み解くのは人間です。「オムツとビール※2」であれば「オムツを買いに来ているのは男性で、子供のオムツを“買いに行かされる”際に、自分への御褒美にビールも買っている」という顧客行動の読み解きができてはじめて施策に活かすことが出来ます。回帰分析ではほとんどのケースでどのデータを比べてもなんらかの相関はでます。ただその相関が意味のある相関なのか、ただの偶然や、実は他の変数と連動した相関なのかを見つけるのはまだまだ人間です。
※ちなみにCRMの世界では有名な「オムツとビール」の事例は実際には存在しない都市伝説という説もありますが、ここではあくまでも例として分かり易いので記載しました。
【価値観を持つのは人間】
先ほど「回帰分析ではほとんどのケースでどのデータを比べてもなんらかの相関はでます」と書きました。この相関は意図的に悪用されることがあります。例えばある地域の犯罪率が特定のマイノリティ(人種、民族、移民、障がい者等)と相関が見えたとしましょう。悪意を持ってこのデータを使えば「治安が悪いのはこの人種のせいであるから排除しなくてはいけない」といったような排斥運動に使われます。しかし実は本当に相関があるデータは特定の人種ではなく、収入格差(や教育水準等)との相関であり、たまたまその人種は過去の歴史的な差別の結果、低収入の層が多かっただけで、収入毎に切り出されたデータを同じサンプル数で比べてみれば罪を犯す率は人種との相関がなかったとしたらどうでしょうか?また仮に特定のマイノリティとの相関が見えたとして、そこにはどのような事実を読み取り、どのような施策に活かすべきでしょうか?データはこのようなことは教えてくれません。
結局のところ、「ビッグデータ」と言っても最後のアウトプットに繋げる「最後の砦」の部分はまだまだ人間が介在しないといけないのです。そんなことから「データサインティスト」と呼ばれる分析専門の技術者が脚光を浴びているわけですが、実は言われていることはCRMが登場した90年代から同じなのです。技術の進歩でできるようになったことと、普遍的な課題、双方を見つめながら上手く情報を活用していきたいものです。

