
LLMサービス開発をリードしてきたAIコンサルタントとLLMエンジニアが、それぞれの視点で企業導入のポイントを解説します。今回の記事は、エンジニアパートです。


LTS入社後、総合的なデータ分析支援プロジェクトに従事し、データ分析研修設計、データ分析サービス開発、在庫・発注予測アルゴリズムの構築、オープンデータ自動取得プログラムの作成を経験。近年は、商品配置の最適化AI開発プロジェクトに従事し、データ分析技術と数理最適化技術を活用した研究開発に取り組んでいる。(2023年11月時点)
AI開発よりも少ない工数で実装できるLLM開発
LLMを活用したプロダクトやサービスを実装する場合、従来のAI開発と比較してスピーディーに進められるという実感を得ています。
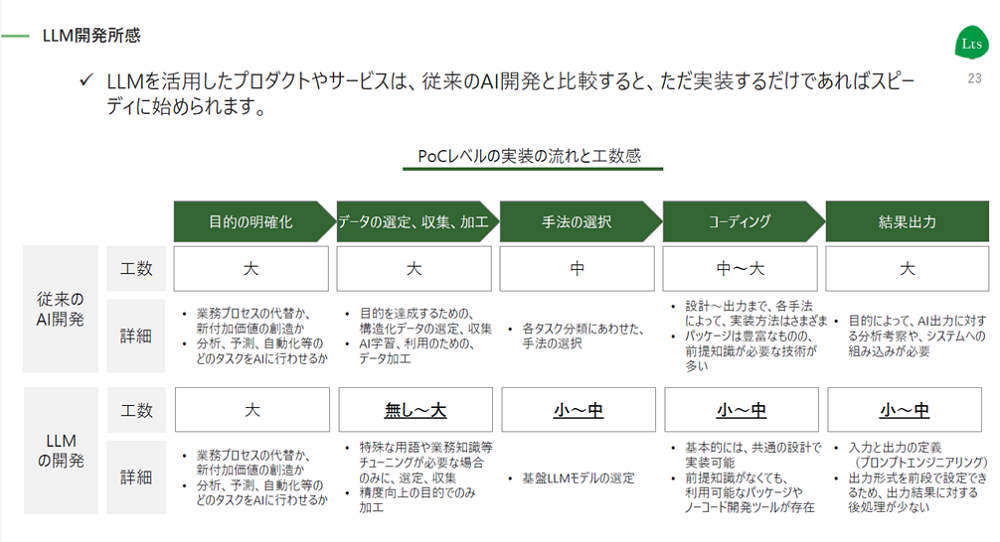
上図は、従来のAI開発とLLM開発のフローです。2つを比較しますと「目的の明確化」に大きな違いはありませんが、「データの選定・収集・加工」は大きく差が生じています。
データの選定・収集・加工の必要工数が少ない
従来のAI開発は、目的に沿った構造化データの収集と選定、そのデータをAIに学習させるためのデータ加工に、非常に工数がかかっていました。この前処理は、従来のAI開発では全体の8割程度の工数を要すると言われています。
一方でLLM開発は、既に大量のデータが学習されており、かつ汎用的に使用できるため、POCレベルの実装であればデータを用意する必要はなく、仮にデータを用意する場合でも少量で済みます。
ビジネス適用する場合は、LLMの精度を向上させるためにデータを用意しますが、データの加工にかかる工数は、従来のAI開発の構造化データの加工工数に比べると非常に少ないです。
手法の選択が容易
また、従来のAI開発は、分析や予測、自動化など、目的に応じてどの手法を選択すべきか考察する必要がありました。適切な選択には各手法の前提知識も必要となり、ある程度の工数がかかります。
一方でLLM開発は、ChatGPTやオープンソースのモデルが基盤LLMモデルとして用意されているため、それらの中から目的に応じてモデルを選ぶだけです。よって、従来のAI開発と比較して非常に少ない工数で済みます。
コーディングの前提知識がなくても使える
従来のAI開発は、コーディング手法に応じて設計から出力までの実装方法はさまざまです。パッケージも豊富にあるため、それらの前提知識がないと技術を使いきれません。そのための技術のキャッチアップまで含めると、非常に工数がかかります。
一方でLLM開発は、モデルの選定やデータのスキームが整えば、基本的にはどのタスクに関しても共通の設計で実装が可能です。加えて、パッケージやノーコード開発ツールが非常に充実しているため、基本的には前提知識が十分になくても利用可能という認識です。
結果出力の対応工数が少ない
従来のAI開発では、目的によってAIの出力データを分析したり、システムに組み込んだりしなければ価値を創出できないという特性がありました。また分析したものをチューニングする作業にも前提知識が必要となるため、これらのキャッチアップも含めると、結果を出力した後工程にも非常に工数がかかります。
一方でLLM開発は、性能向上を目的としたチューニング作業には多少工数が必要ですが、従来のAI開発と比較すると前提知識が十分になくても対応可能ですので、結果出力後の工数は少なくなります。
POCレベルでの実装の流れを工数感とともに説明しましたが、このようにLLM開発は従来のAI開発と比較して非常に工数が少なく、簡単に敷居が低く始められるものです。
LLM開発における目標観点
POCレベルの実装であれば、上記で説明した通り従来のAI開発よりも簡単に開発できますが、ビジネス価値を創出できるまで昇華させたい、ビジネス提供した上でより効果的なLLMモデルを活用したサービスを作っていきたいという場合は、もう少し開発の観点が必要になってきます。
エンジニアの観点で「うまい」「はやい」「やすい」と言われるものがあります。この3つの観点はLLMに関しても例外ではなく、これらの観点を持ちながら実装していくことがポイントです。

うまい
まず「うまい」ですが、LLMの場合は「回答の精度」です。LLMの出力する回答が正確かつ解釈性が高くて、上手な回答をしてくるという意味での“上手い”。そして、ビジネス的に有用かつ効果的に「業務適合」でき、業務においておいしいという意味での“旨い”ということを意識した開発が必要です。
はやい
「はやい」においては、LLMはまだ開発が黎明期で、多種多様な手法が矢継ぎ早に新技術として出てきますので、これらのキャッチアップをひたすら早くしていく「情報収集」のキャッチアップ力が“早い”という観点が一つ。そして「開発検証」でキャッチアップしたものをしっかりと実装、検証するスピードが“速い”という点もしっかりと意識して開発していく必要があります。
やすい
最後の「やすい」ですが、これはLLM以外のエンジニアリングに言えることです。特にLLMに関しては「計算資源」を大量に使うことになるので、このようなリソースの配分や計算速度が最適化されていて開発コストが“安く”なっているか、という点が一つ。また「ユーザビリティ」においても、ユーザーが使い“やすい”設計になっているのかといった、点を意識した研究開発が必要になってくると考えています。
LLM開発における課題
これらの観点を意識して開発する場合、従来のAI開発では画一的な方法論が存在していましたが、LLMに関してはまだ黎明期にあるため、画一化された方法論が存在していません。
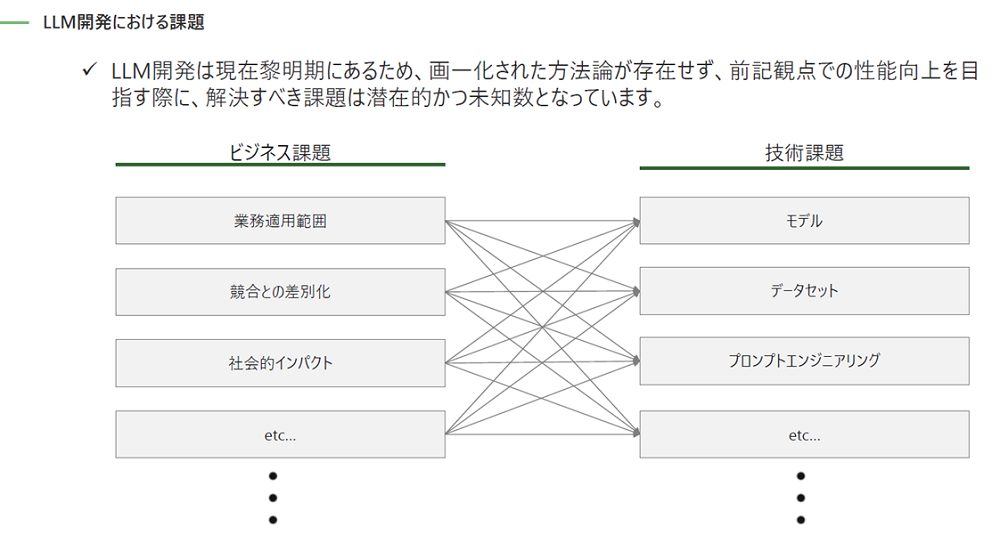
よって、業務適用範囲や競合との差別化、社会的インパクトなどのビジネス課題に対して、具体的に適用していく技術的課題は未知数というのが現状です。従って、LLM開発領域においては、実際に自社のサービスを開発・実装して実践的に学んでいくことが、大きなスキームになってくると考えています。
とにかく早く始めてみましょう!!
このような状況から、とにかく早く始めてみるのがよい!というのが、エンジニアの視点です。
ここまで説明してきたように、LLM開発は非常に敷居が低く、ノーコードで10分程度の時間があれば開発ができます。実践しながら開発のベースを作り、それに対して欲しい機能が徐々に出てくると思いますので、走りながら感覚をつかんでいくことがポイントになると思います。
まずはさまざまなオープンソースモデルを使用したり、データセットが自社にたまっていたりするなら、データ投入をして実装してみる、そして探索的に結果を見てみる、を繰り返してナレッジをためていくことが重要です。
現状LLM開発領域で先進的な取り組みをしているのは、ごく一部のIT企業のみです。この領域では、まだどこに技術的な課題があるのか、それに対してどのように対応していくのかは一般的に広まっていません。ですので、まだ皆がスタートラインにいます。早く始めた企業ほどナレッジも溜まり競合との差別化ができる領域だと思います。
その際に、しっかりとビジネスで価値を出すためには、上記でお伝えしたような「うまい」「はやい」「やすい」を意識しながら取り組んでいくことが重要です。
技術的にもビジネスにおける検証は始まったばかりで、今後、新たな技術が出てくる可能性も高く、ベストプラクティスといわれるようなケースも特段あるわけではありません。この状況を活かして取り組みを行っていけば、先進的な取り組み事例として発表できる機会も増えていくのではないかと思います。
それ自体が、ビジネスの生産性だけでなく、外部へのプロモーション価値も含めて効果を発揮できる点だと思いますので、とにかく早く始めてナレッジをためていただければと思います。

ライター

CLOVER編集部員。メディアの立ち上げから携わり、現在は運営と運用・管理を担当。SIerでSE、社会教育団体で出版・編集業務を経験し、現在はLTSマーケティングGに所属。趣味は自然観賞、旅行、グルメ、和装。(2021年6月時点)


